
Es gibt manche Momente, da wird der Glaube an die Bürokratie ein bisschen erschüttert. Und das bei einem Politikwissenschaftler. Die ganze Geschichte meiner Masterarbeit.
![]()

Eine alte Datenjournalistenregel besagt: Wenn Du es einem Praktikanten geben willst, schreib einen Scraper. Stimmt nicht immer, aber oft. Denn grundsätzlich geht das sehr einfach. Ein Tutorial.
![]()
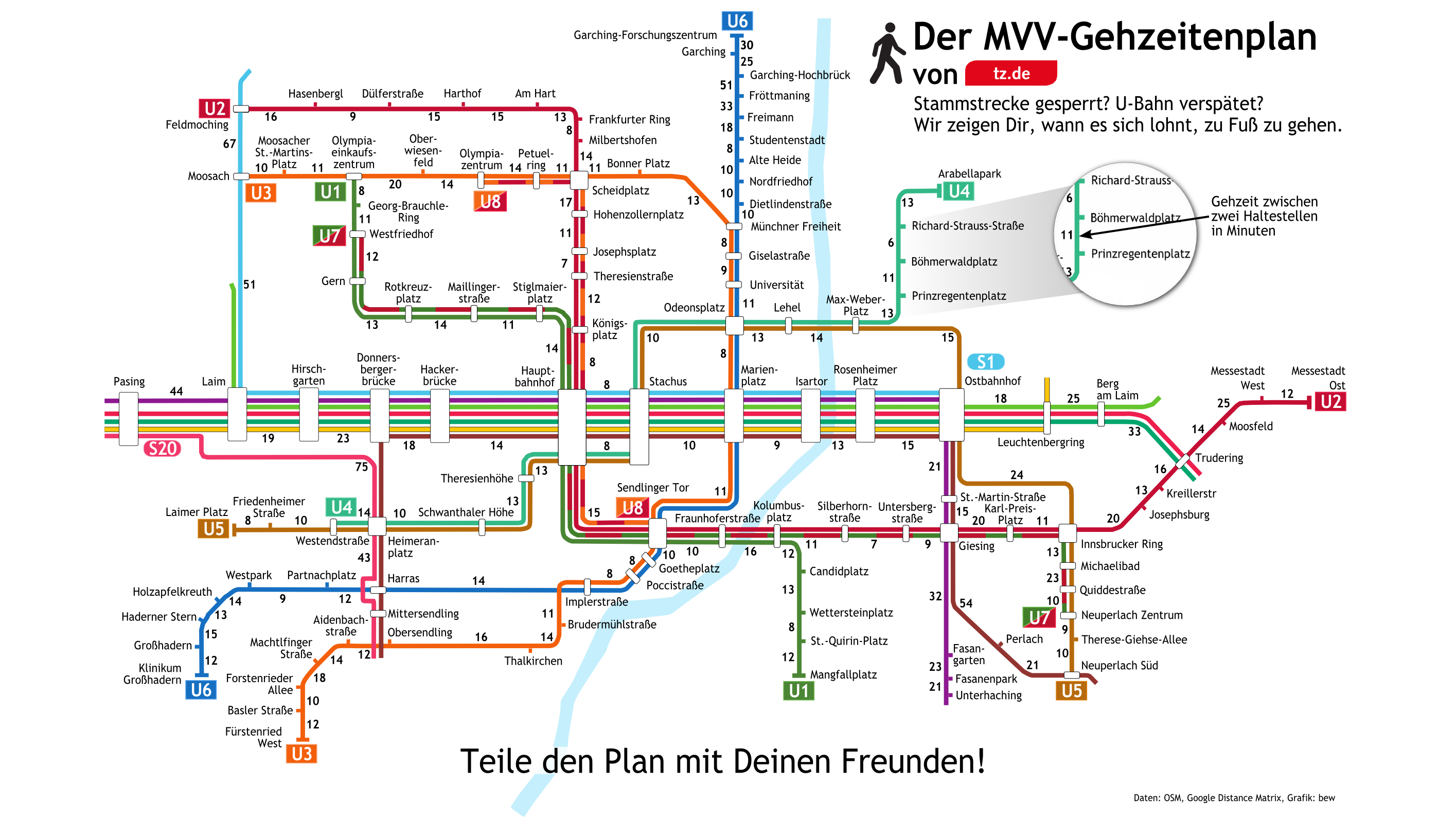
Mit Kartendaten lassen sich tolle Analysen und Anwendungen bauen. Ich bin ein großer Verfechter der Open Street Map (merkt man kaum in diesem Blog). Mit deren Hilfe habe ich auch eine etwas andere Innenraumkarte für die Münchner öffentlichen Verkehrsmittel gebaut.
![]()

Danke, Google Maps. Wer hätte vor zwanzig Jahren gedacht, dass man heute keinen Landkarten mehr lesen können muss, um an sein Ziel zu kommen? Aus journalistischer Sicht lassen sich mit Kartendaten zudem richtig coole Geschichten erzählen. Und damit meine ich nicht, irgendwelche Punkte auf eine Karte zu setzen, hinter denen sich Popups öffnen. Ich meine Geschichten, die mit geografischen Einheiten spielen.
![]()
Wie oft denkt man über folgende Fragen nach:
Ganz alltägliche Fragen, für die es zahlreiche Apps gibt, um sie zu beantworten. Aber: Es gibt auch ein Tool, dass alle diese Fragen beantworten kann – und darüber hinaus noch viele mehr. Und das beste: Es bietet die Antworten maschinenlesbar an, unter einer freien Lizenz. Es geht um die Open Street Map.
Das Projekt exisitert seit 2006 und hat sich zum Ziel genommen frei verfügbare Geodaten anzubieten, damit die Nutzer daraus Landkarten bauen, oder per GPS navigieren können. Während die normalen Kartenabieter, wie Google oder Apple, ihre Karten unter Lizenz stellen, können wir die OSM-Daten frei benutzen, nur eine kleine Quellenangabe ist fällig.
Wie wohl die meisten Geodaten besteht die OSM aus drei Hauptbestandteilen: Punkten (Nodes), Kanten (Ways) und Verbindungen (Relations). Die haben nicht nur Koordinaten, sondern können auch Key-Value-Paare besitzen, die beschreiben, was die einzelnen Bestandteile sind. Telefonzellen heißen zum Beispiel: amenity = telephone, Bahnhöfe railway = station. Diese Kombinationen heißen: Tags. (Zehn nützliche und/oder lustige Tags habe ich hier zusammengeschrieben)
Besagte Telefonzellen können dann aber noch mehr Infos haben: Den Betreiber (operator = Deutsche Telekom AG), eine Angabe, ob sie überdacht sind (covered = yes/no) oder sogar die Telefonnummer. Einen guten Überblick darüber, was ein Punkt für Informationen haben kann, liefert Nominatim (einfach mal nen Ort eingeben).
Über die OSM-Karte kann man sich das anzeigen lassen, zur automatisierten Abfrage gibt es eine API – die Overpass API. Inzwischen hat die so viele Instanzen, dass man damit ordentlich arbeiten kann. (Mein Haupt-Nachschlagewerk dafür ist das Wiki hier, mit vielen Beispielen.) Sehr cool finde ich, dass man mit Query-Forms sogar ohne ein Skript zu schreiben, abfragen kann. Und auch die zahlreichen Exportoptionen (JSON, XML, CSV) reichen voll aus. Wie so eine Beispielquery in R aussehen kann:
|
1 2 3 4 5 |
library(RCurl) myQuery <- paste0("[out:csv(::id,::type,\"name\",::lat,::lon)];area[\"name\"=\"München\"];node[\"railway\"=\"station\"](area);(._;>;);out%20body;") url <- paste0("http://overpass-api.de/api/interpreter?data=", myQuery) response <- getURL(url, .encoding = "UTF-8") response_csv <- read.csv(text = response, head = TRUE, sep="\t", stringsAsFactors = FALSE) |
Wer sich nicht so gut mit APIs auskennt, oder ersteinmal experimentieren will: Es gibt einen super Einstieg. Overpass Turbo. Damit kann man sehr schnell ausprobieren, was möglich ist mit der OSM, und wie eine Suchabfrage aussehen kann. Im Idealfall kann man sie über die Overpass Turbo auch gleich ausführen. Ein Beispiel: Wir wollen wissen, wo in München Bahnhöfe sind. Ich weiß nichtmal, in welcher Bounding Box (also von welchen Koordinaten umgeben) München liegt. Die OSM hat aber auch einen Geocoder, der aus Orten Koordinaten macht.
In der Overpass Turbo gibt es einen Wizard, bei dem ich meine Suchanfrage ganz easy eingeben kann:
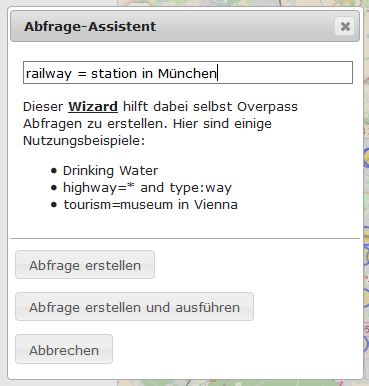
Es baut daraus die Abfrage – ich muss gar nichts machen.
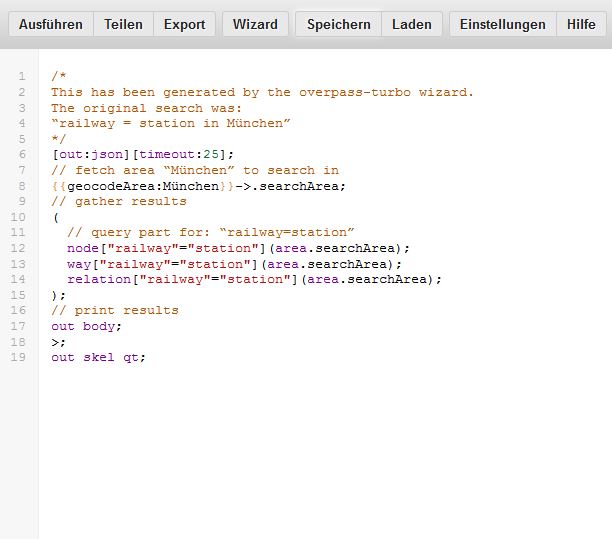
Natürlich könnte ich hier noch manuell was verändern. In der Overpass API würde ich zum Beispiel ganz oben ein [out:csv(::id,::type,"name")]; einfügen, um eine CSV-Ausgabe zu erzeugen (und ich kann genau festlegen, welche Felder ich gerne hätte. Auch kann ich mit dem Befehl area[name="München"] den Ort händisch festlegen. Es kann sich auch anbieten, für die Bahnhöfe nur nach Nodes zu suchen, oder in anderen Fällen nur nach Straßen.
Overpass Turbo schickt seine Anfrage an die Overpass API und gibt das Ergebnis als Karte zurück.
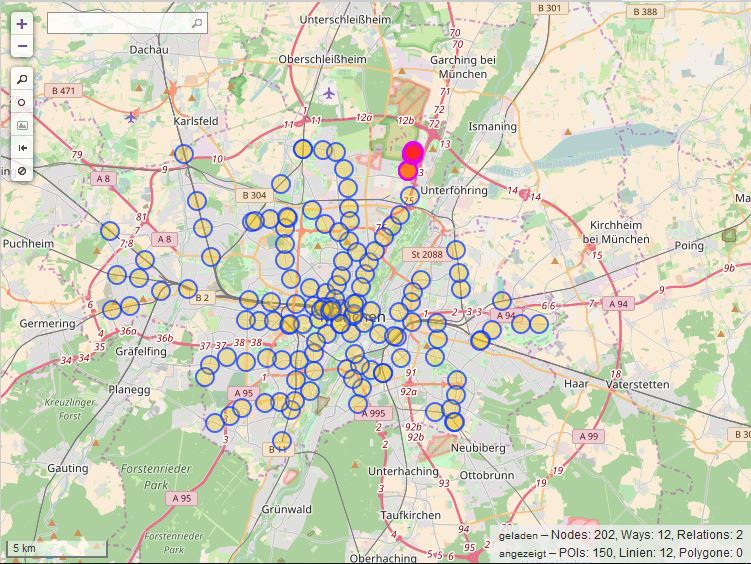
Das Ergebnis lässt sich jetzt direkt als GeoJSON, GPX oder KML exportieren. Für CSV oder XML kann man die Abfrage für die Overpass API konvertieren lassen. Overpass Turbo hilft auf jeden Fall zu checken, ob die Suchbegriffe die richtigen sind. Für größere Abfragen muss man dann aber die Overpass API nutzen, Turbo hängt sehr schnell.
Die Daten kann ich dann super visualisieren, zum Beispiel mit QGIS. Ich kann sie aber auch als Ausgangspunkt für eine weitere Analyse nutzen. Es gibt auch Anwendungsfälle, in denen mit OSM-Höhendaten 3D-Modelle gebaut wurden. Der Fantasie sind da sehr wenige Grenzen gesetzt.
![]()
Eine kleine Zusammenstellung von verrückten und hilfreichen Tags der Punkte, Wege und Relationen der OpenStreetMap.
building=yes ist der am meisten verwendete Tag in der OpenStreetMap. Er zeigt an: Das hier ist ein Gebäude.
emergency=fire_hydrant zeigt die Position von Hydranten.
highway = ... Der Klassiker für die Suche nach Straßen. Es gibt zahlreiche Einschränkungen, zu Beispiel residential (Wohngebiet), motorway (Autobahn), pedestrian (Fußgängerzone)
highway=bus_stop zeigt Bushaltestellen.
maxspeed = 50 sucht nach Straßen, bei denen die Höchstgeschwindigkeit (in km/h) hinterlegt wurde.
religion=christian zeigt christliche Gebetsstätten – klappt auch mit anderen Konfessionen.
ice_cream = yes/no gibt an, ob es in einem amenity = restaurant/cafe oder shop = ice_cream Eis gibt.
wheelchair=yes zeigt behindertengerechte Toiletten an.
boundary=administrative + admin_level=2 gibt Verwaltungsgrenzen zurück. In diesem Fall die Staatsgrenze. Geht aber teilweise runter bis auf Stadtbezirksteile. Ein Überblick hier.
name:de:1953-1990=Ernst-Thälmann-Straße Das „de“ und die Jahreszahlen schränken ein, wie die Straße früher hieß. Bietet sich natürlich in Deutschland an, bei den Umbenennungen nach der DDR.
Die OpenStreetMap lebt ja von den Tags – deswegen sind sie auch sehr gut dokumentiert. Ich schaue am liebsten hier im OSM-Wiki und hier bei Taginfo. Sehr anschaulich ist auch der Eintrag „How to map a“.
![]()

Studenten in München haben es nicht leicht. Die Mietpreise sind der Wahnsinn, es gab großen Stress um das relativ teuere Semesterticket – und dann sind die Bibliotheken noch so voll. Das war zumindest der Anlass, weshalb die Universitätsbibliothek der LMU Ende 2016 ein neues Tool gestartet hat: Den Platzfinder. Zusammen mit einer Parkscheibe, die Studierende bekommen, wenn sie die Bibliothek betreten, ermitteln die Bibliotheksmitarbeiter, wie voll ihre Bibliothek gerade ist – und tragen das in ein Onlineformular ein (Was natürlich auch sehr fehlerbehaftet ist – aber die Daten sind das Beste, was wir haben).
Auf der Webseite der Uni-Bibliothek können Studierende dann checken, wie voll ihre „Lieblingsbib“ ist.
Für M94.5 wollte ich herausfinden, welche Bib am vollsten ist – und wie sich das im Tagesverlauf verändert.
Die Seite der LMU gibt SVGs mit Prozentwerten für die Füllung aus, die in den Balkendiagrammen angezeigt werden. Mit Python und der Bibliothek BeautifulSoup konnte ich also easy die Daten auslesen und in ein CSV speichern:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
#!/usr/bin/python # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import urllib import re import csv from datetime import datetime r = urllib.urlopen('http://www.ub.uni-muenchen.de/arbeiten/platzfinder/index.html').read() soup = BeautifulSoup(r, "lxml") iframes = soup.find_all("iframe") csvdata = [] print "Sammle Daten" for i in iframes: r1 = urllib.urlopen(i["src"]).read() iframe = BeautifulSoup(r1, "lxml") name = iframe.find("div", {"id": "chart_text1"}).get_text().encode('utf-8') data = iframe.find_all("script")[1].string data = data.replace("'", '"') p = re.compile('var data = google.visualization.arrayToDataTable\(\[\[(.*?)\],\[.+"\,(.*?)\]\]\)') m = p.search(data) try: lst = str(m.group(2).encode('utf-8')).split(",") except: lst = str(m.group(0).encode('utf-8')).split(",") if lst[0] == "1": name = name.strip() fill = "Geschlossen" empty = 0 else: name = name.strip() fill = lst[0] empty = lst[1] csvdata.append((name, fill, empty)) print "Schreibe: ", i["src"] # open a csv file with append, so old data will not be erased with open('data.csv', 'a') as csv_file: writer = csv.writer(csv_file, delimiter=';', lineterminator='\n') # The for loop print "Schreibe CSV" for name, fill, empty in csvdata: writer.writerow([name, fill, empty, datetime.now()]) print "Fertig" |
Damit das Ganze alle 15 Minuten laufen kann – in den Zeiten, in denen die Bibliotheken geöffnet haben – habe ich zu einem Trick gegriffen. Das Pythonskript lag auf meinem Webspace, der Python vorinstalliert hat. Daneben lag ein einfaches Shell-Startskript für das Python. Dieses Skript rufe ich über über einen Cronjob auf. In meinem Fall habe ich Cronjob.de benutzt (ein Skript ist kostenlos, weitere kosten ab 99 Cent pro Monat) – es gibt Alternativen.
Dann hieß es: Warten. 1,5 Monate lang etwa. Das CSV füllte sich immer weiter, ohne, dass ich irgendwas tun musste.
Dann hieß es: Auswerten. Dafür habe ich das CSV gedownloaded und in R eingelesen.
|
1 2 3 4 5 6 7 8 |
library(dplyr) library(ggplot2) library(lubridate) library(extrafont) library(grid) colN <- c("Bibliothek", "Belegt", "Leer", "Datum") d <- read.csv2("data.csv", stringsAsFactors = TRUE, col.names = colN, colClasses = c("factor", "numeric", "numeric", "POSIXct"), header = FALSE, encoding = "UTF-8", na.strings = "Geschlossen") |
Schon beim ersten Rumspielen hat sich gezeigt: Weihnachten ist ne blöde Zeit für den Datensatz. Im Vergleich zu den anderen Zeiten lag die Belegungsquote ziemlich weit unten. Das hieß für mich: Weihnachten raus.
|
1 2 3 4 5 6 7 |
#Remove Test-Data and create new columns, filter out Christmas-Time d %>% filter(Datum > "2016-12-17 23:45:29") %>% filter(Datum <= "2016-12-23 23:59:59" | Datum >= "2017-01-02 00:00:00") %>% mutate(weekday = weekdays.POSIXt(Datum), hour = hour(Datum)) -> w w$weekday <- factor(w$weekday, levels = c("Montag", "Dienstag", "Mittwoch", "Donnerstag", "Freitag", "Samstag", "Sonntag")) |
Dann folgten die einzelnen Analysen. Zunächst wollte ich wissen (und natürlich auch plotten), wie groß der Unterschied zwischen Wochentag und Wochenende in den Bibliotheken ist.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# create tbl_df for weekend and weekday with mean per hour w %>% select(Bibliothek, Belegt, weekday, hour, Datum) %>% filter(complete.cases(.)) %>% filter(weekday != "Samstag" & weekday != "Sonntag") %>% group_by(hour) %>% summarise(mean(Belegt)) -> week w %>% select(Bibliothek, Belegt, weekday, hour, Datum) %>% filter(complete.cases(.)) %>% filter(weekday == "Samstag" | weekday == "Sonntag") %>% group_by(hour) %>% summarise(mean(Belegt)) -> weekend ## Plotting Weekday vs Weekend svg("week_vs_weekend.svg", pointsize = 28, width = 11.78, height = 8.39) ggplot() + geom_line(data = weekend, aes(hour, `mean(Belegt)`), color = "#590086", size = 1.3) + geom_area(data = weekend, aes(hour, `mean(Belegt)`), color = "#dd9aff", alpha = 0.2) + geom_line(data = week, aes(hour, `mean(Belegt)`), color = "#865900", size = 1.3) + geom_area(data = week, aes(hour, `mean(Belegt)`), fill = "#ffd686", alpha = 0.6) + labs(title = "Durchschnitts-Belegung im Tagesverlauf", subtitle = "Braun: Werktag, Blau: Wochenende") + ylab("Belegung in Prozent") + xlab("Uhrzeit") + theme_bw() + theme(text = element_text(size = 12), plot.margin = unit(c(1, 1, 4, 1), "lines"), panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(), panel.border = element_blank()) dev.off() |
Dann wollte ich wissen, wie die unterschiedlichen Wochentage sich einzeln unterscheiden. Das könnte man in ggplot mit Facets lösen. Ich wollte das ganze aber in einem Plot. Das hieß: Rumspielen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Plotting Every day by hour w %>% select(Bibliothek, Belegt, weekday, hour, Datum) %>% filter(Datum <= "2016-12-23 23:59:59" | Datum >= "2017-01-02 00:00:00") %>% filter(complete.cases(.)) %>% group_by(weekday, hour) %>% summarise(mean = mean(Belegt)) -> weekday_by_hour svg("weekday_per_hour.svg", pointsize = 28, width = 11.78, height = 8.39) #png("weekday_per_hour.png", pointsize = 28, width = 500) g1 <- ggplot(weekday_by_hour, aes(x = interaction(weekday, hour, lex.order = TRUE), y = mean, group = 1)) + geom_line(colour = "#008659", size = 1.3) + geom_area(fill = "#86ffd6", alpha = 0.5) + coord_cartesian(ylim = c(0, 65), expand = FALSE) + annotate(geom = "text", x = seq_len(nrow(weekday_by_hour)), y = -1, label = weekday_by_hour$hour, size = 2) + annotate(geom = "text", x = 9 + 16 * (0:6), y = -4, label = unique(weekday_by_hour$weekday), size = 5) + theme_bw() + theme(text = element_text(size = 12), plot.margin = unit(c(1, 1, 4, 1), "lines"), axis.title.x = element_blank(), axis.text.x = element_blank(), panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(), panel.border = element_blank()) + geom_hline(yintercept = mean(weekday_by_hour$mean), linetype = 3) + ylab("Durchschnittsbelegung in Prozent") g2 <- ggplot_gtable(ggplot_build(g1)) g2$layout$clip[g2$layout$name == "panel"] <- "off" grid::grid.draw(g2) dev.off() |
Und dann das Highlight. Ich dachte mir, ein bisschen Bewegung schadet nicht. Deswegen wollte ich ein GIF erstellen, dass für jede Stunde des Tages für jede Bibliothek die Durchschnittsbelegung angibt. Das Skript sollte mir die einzelnen Stunden automatisch ausgeben, damit ich daraus nur noch ein GIF bauen muss. (Das würde auch direkt in R gehen, mit diesem Package)
Ich habe meinen w-Dataframe nochmal kopiert, weil ich die Rohdaten-NAs durch 0 ersetzt habe. Das wollte ich mir im Original-Datensatz nicht zerschießen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
## # Create PNG for each Hour of the Day ### #Make copy of w-df w_nas <- w #replace NAs with 0 w_nas[is.na(w_nas$Belegt),]$Belegt <- 0 #Debugging needed for the hjust of plot.title for (i in 8:23){ w_help = NULL w_nas %>% filter(hour==i) %>% group_by(Bibliothek) %>% summarise(mean = mean(Belegt)) -> w_help print(head(w_help)) png(paste0(i,".png"), width = 500, units = "px") p <- ggplot(w_help, aes(Bibliothek, mean)) + geom_bar(stat="identity", fill = "#008659") + coord_flip() + theme(text = element_text(family = "Arial"), axis.title = element_blank(), plot.title = element_text(face = "bold", size = 18)) + labs(title = paste("Besetzte UB-Plätze um", i, "Uhr")) + scale_y_continuous(limits = c(0, 100)) print(p) dev.off() } |
Fertig.
Das Ergebnis gibt es hier.
![]()
Manchmal möchte ich echt nicht mit mir auf Facebok befreundet sein.
Da spüle ich monatelang im Frühjahr 2016 sonnigen Indiencontent in die Timelines, mit einem damaligen Blogprojekt „Ab nach Indien“ (Das es hier noch archiviert gibt).
Und jetzt: Ein neuer Blog.
Denn in dem einen Jahr ist viel passiert: Ich habe bei der Süddeutschen Zeitung in der Entwicklugsredaktion ein Praktikum gemacht. War dort unter anderem an zwei Großprojekten beteiligt: Über den Amoklauf von München und über die „Internet-of-Things“-Suchmaschine Shodan. Ich habe zum ersten Mal richtig als Datenjournalist arbeiten können, mit Leuten, die das hauptberuflich machen. Inzwischen arbeite ich neben meiner Masterarbeit (die tatsächlich auch was mit Daten zu tun) bei Merkur.de/tz.de und BR PULS. Zumindest bei Merkur.de mache ich auch Datenjournalismus, zusammen mit meinem ifp-Kameraden und Medieninformatiker Michael Haas.
Inzwischen ist die Zahl unserer kleinen Projekte so gewachsen, dass mir bald der Überblick fehlt. Ich habe aber immer gemerkt, wie cool es war, wenn andere Leute schon mit ähnlichen Tools und Vorgehensweisen gespielt hatten – und ihre Erfahrungen geteilt haben. Das will ich hier auch machen.
Es wird vor allem darum gehen, wie ich meine/unsere Projekte angegangen und vorgegangen bin. Und natürlich werde ich auch ein bisschen über die Tools schreiben. Um die geht es aber nur am Rande.
Durch die weitere Nutzung der Seite stimmst Du der Verwendung von Cookies zu. Weitere Informationen
Die Cookie-Einstellungen auf dieser Website sind auf "Cookies zulassen" eingestellt, um das beste Surferlebnis zu ermöglichen. Wenn du diese Website ohne Änderung der Cookie-Einstellungen verwendest oder auf "Akzeptieren" klickst, erklärst du sich damit einverstanden.