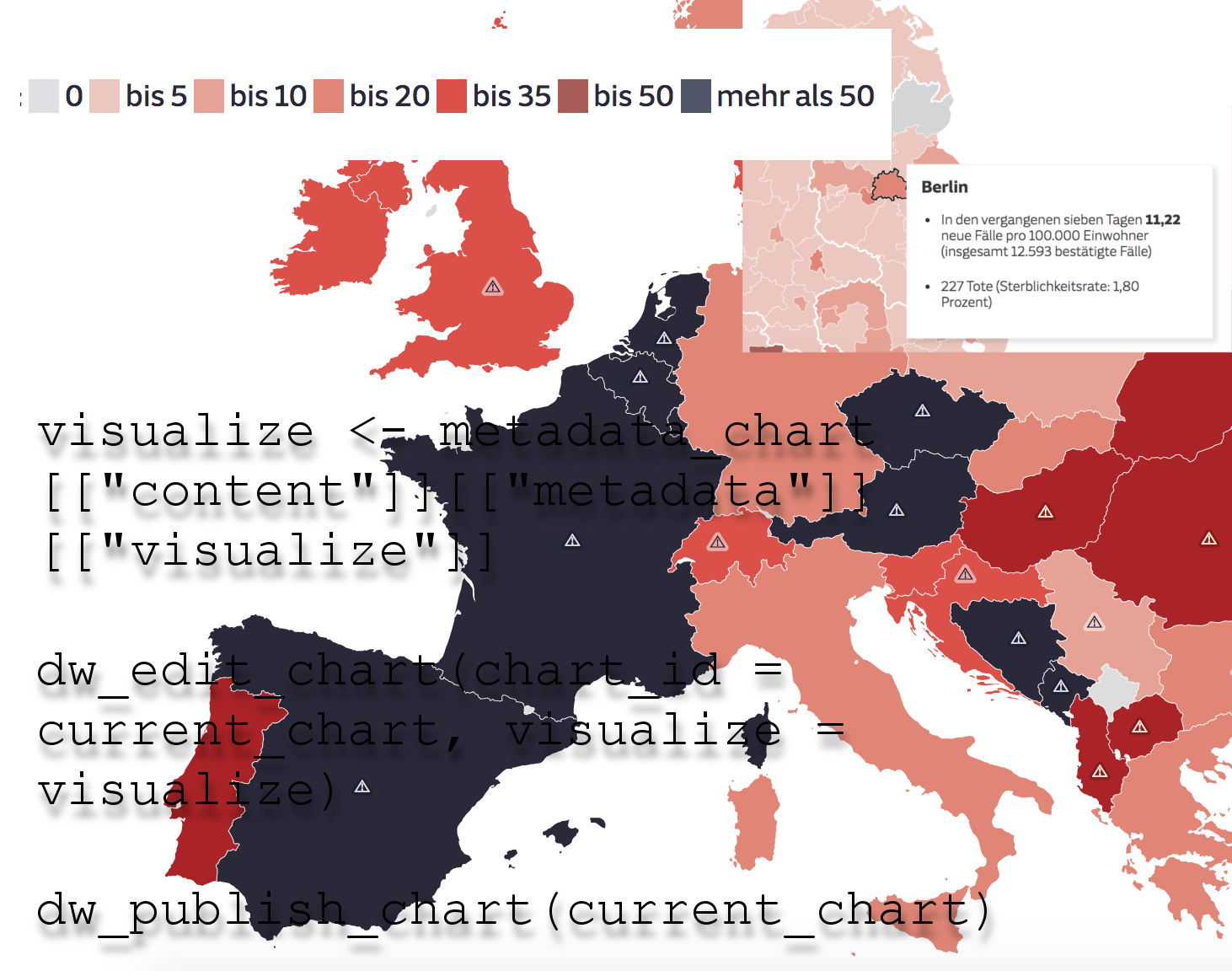
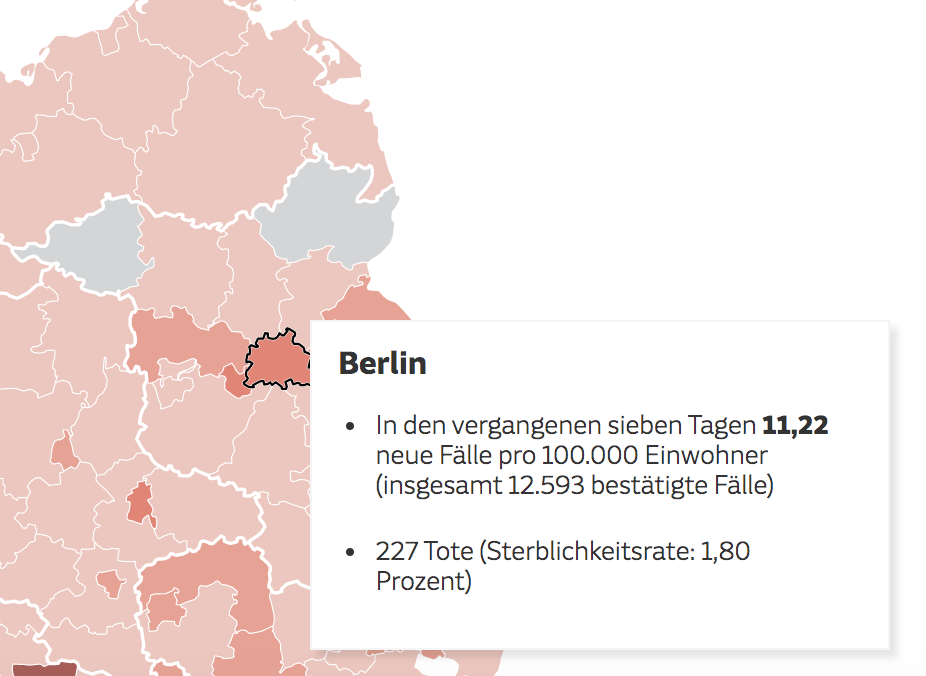
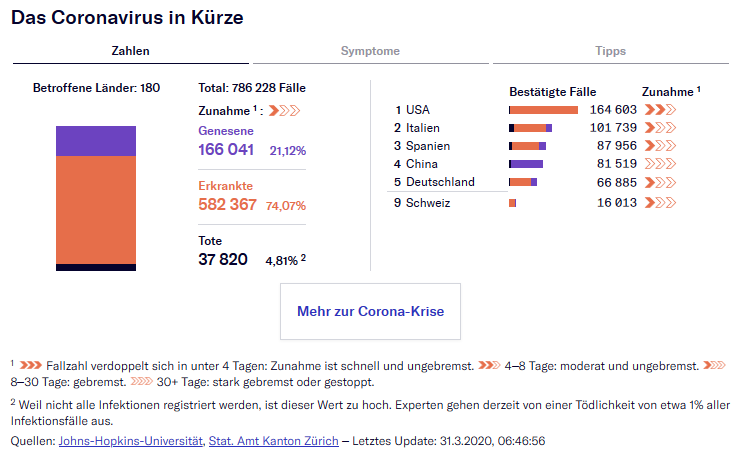
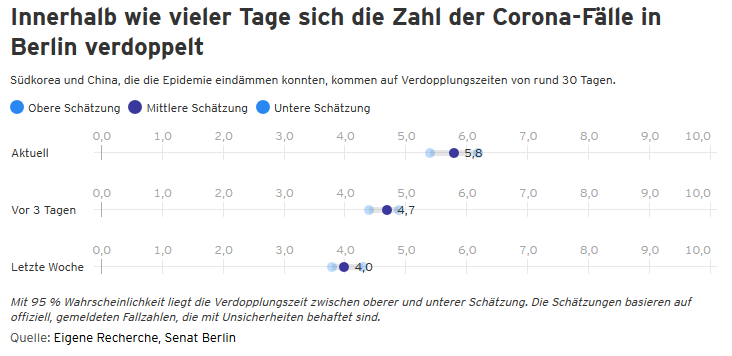
Mit meiner Kollegin Anna Behrend aus der Zentralredaktion von NOZ, SHZ und SVZ in Hamburg habe ich neulich in einem Webinar des Netzwerk Recherche über genau dieses Thema diskutiert. Wobei man fairerweise sagen muss: Im Grunde waren wir uns ziemlich einig. Aber ich finde: Die Frage macht im Jahr 2020 total Sinn. Deswegen heute auch ein Blogpost dazu: Sollten Journalisten Programmieren können/lernen?
Ich bekomme immer wieder mit, wie KollegInnen im Datenjournalismus oder im Storytellingbereich gefragt werden, ob man denn als JournalistIn heute auf jeden Fall eine Programmiersprache können muss. Ein spannendes Thema, finde ich.
Ziemlich eindeutig ist die Antwort für Menschen, die als DatenjournalistInnen arbeiten wollen: Ja, lernt Programmieren! Die Szene hat sich immer mehr professionalisiert, man arbeitet in der Regel mit Menschen zusammen, die auch Coden – oder hilft Menschen bei Problemen, die Code vielleicht einfacher/schneller/besser lösen kann.
Die Frage hat Björn Schwentker bereits 2015 auf der Netzwerk Recherche-Jahrestagung für DatenjournalistInnen deutlich beantwortet: „Ich persönlich glaube, dass man Programmieren können sollte.“
Für alle anderen JournalistInnen wäre eine Antwort auf die Frage aber natürlich auch interessant: Ich denke, das kommt sehr darauf an, ob man das auch lernen möchte und was man sich davon verspricht.
Man kann auch in klassischen Recherchen von eigenen Datenauswertungen profitieren (man denke an Finanz-, Gesundheits- oder Sozialpolitik, viele Sportarten oder Wirtschaftsthemen). Es kann in manchen Bereichen Sinn machen, wenn man Algorithmen nicht nur beschreiben, sondern sogar (nach)programmieren kann. Und es macht halt auch einfach Spaß, etwas neues zu lernen, um „Probleme“ zu lösen.
Andererseits muss man so eine Sprache aber natürlich auch lernen. Ihre Syntax, ihre Worte, ihre Stärken, vielleicht auch ihre Schwächen. Und wenn man sich damit noch gar nie beschäftigt hat, muss man sich nebenbei auch noch viel über das Internet, Webschnittstellen, Datenstrukturen, Datenbanken und vieles mehr beibringen. Das kostet Zeit und braucht Frustrationstoleranz. Aber wenn man ein Programm geschrieben hat, das eine bestimmte Funktion ganz smooth und störungsfrei ausführt, fühlt sich das manchmal ein bisschen an wie Magie.
Ich hab mal versucht, fünf Gründe zu beschreiben, warum Programmieren für Journalisten sinnvoll sein kann. Ein Teil davon doppelt sich ein bisschen mit meinem Blogpost zur Automatisierung.
1. Schnelligkeit
Im Journalismus zählt oft jede Minute. Bei Wahlen oder generell bei Veröffentlichungen, die man vorhersehen kann (Hurrikans, Unfallatlas, Abstimmungen aller Art), helfen vorgeschriebene Skripte dabei, dass Aufgaben schneller umgesetzt werden, als wenn das Menschen machen müssen.
Das gilt auch zum Beispiel für das Downloaden und Verarbeiten von vielen Daten, zum Beispiel hundert ähnlichen PDFs zu einem bestimmten Thema. Oft kann man die Arbeitszeit viel sinnvoller einsetzen.
2. Tiefe oder Personalisierung
Manchmal ist es auch gar nicht möglich, dass Menschen eine Menge an Informationen händisch verarbeiten (looking at you, Panama Papers). Dann bleibt nur der Ausweg Computer. Skripte können dann helfen, über große Datenmengen einen Überblick zu bekommen, sie auszuwerten, oder darin zu suchen. Man kann ein Thema dadurch tiefer ausleuchten, als es bei händischer Recherche geht.
Andererseits können Journalisten, die programmieren auch persönlichere Inhalte anbieten. Indem Datensätze nach bestimmen Merkmalen (Region, Alter, Geschlecht, Einkommen) aufgetrennt werden, und sich die Nutzer darin selbst verorten können.
3. Zugänglichkeit
Manche Daten sind vielleicht auch gar nicht in einem tabellarischen Format. Die Klassiker: JSON oder XML, Daten, die man zum Beispiel über APIs bekommt.
Mit ein bisschen Hustle kann man die zwar für Excel et al passend machen – aber in der Regel haben verschachtelte Daten ja auch einen Zweck. Viel praktischer ist es dann doch, wenn man mit diesen Daten direkt weiterarbeiten kann. Und das geht nunmal am einfachsten mit Code, den Journalisten programmieren.
4. Transparenz
Ja, ich kann auch nach einer Excelrecherche Punkt für Punkt mitschreiben, welche Änderungen ich an den Daten vorgenommen habe, was ich ausgewählt habe, welche Buttons ich gedrückt habe. Aber das ist furchtbar unübersichtlich.
Gerade JournalistInnen (aber auch WissenschaftlerInnen) steht es daher gut zu Gesicht, wenn sie ihre Daten und Skripte öffentlich zugänglich machen. Ein Code zeigt mir Schritt für Schritt, was von den Input-Daten bis zu den Output-Daten passiert ist. Darin lassen sich auch Fehler finden, ganz klar. Aber lieber einen Fehler finden und korrigieren, als etwas falsches stehen zu lassen.
Transparenz von Code und Daten geht natürlich nicht bei allen Recherchen (Quellenschutz, Datenschutz, etc.) – aber vermutlich in sehr vielen Fällen. Allerdings muss dafür auch Arbeitszeit investiert werden, denn die Aufbereitung des Codes kostet Zeit.
Im Idealfall kann dann aber auch jede/r zuhause eine Datenanalyse nachvollziehen.
5. Reproduzierbarkeit
Was uns zum letzten Punkt bringt. In der Wissenschaft gilt der große Anspruch, dass Forschung reproduzierbar, also wiederholbar, sein soll. Das macht auch in vielen (wenn nicht fast allen) datenjournalistischen Analysen Sinn. Wenn ich einen Datensatz betrachte, und ihm identische Fragen stelle, sollte die Antwort die gleiche sein. Nur dann kann ich mich darauf verlassen, dass die Aussagen, die ich treffe, auch stimmen.
Außerdem können im besten Fall KollegInnen in anderen Häusern eine Recherche wiederholen. Klingt vielleicht erstmal blöd – aber geht es uns nicht im Grunde darum, Missstände aufzudecken? Wenn man sich dabei gegenseitig unterstützen kann – warum sollte man das nicht tun? Die exklusive Geschichte hatte man ja in der Regel schon bei der eigenen Veröffentlichung.
Welche Programmiersprachen sollten JournalistInnen lernen?
Das ist wohl die häufigste Frage, nach der im Titel dieses Blogposts. Dabei ist meine Antwort: a) „es kommt drauf an“ oder b) „es ist eigentlich relativ egal“. Was meine ich damit?
Für spezielle Zwecke haben sich verschiedene Sprachen herausgebildet: Javascript ist zum Beispiel der Standard für Interaktivität auf Webseiten, PHP steuert oft die Server hinter Homepages, viele Android-Apps werden mit Java geschrieben. Wenn man schon genau weiß, in welchem Bereich man unterwegs sein wird, kann man sich so orientieren.
Andererseits habe ich die Erfahrung gemacht: Wenn man die Grundzüge des Programmierens verstanden hat, kann man relativ einfach auch zwischen Sprachen wechseln. Es wird nur manchmal etwas mühsam, wenn man aus Versehen Fehler einbaut, weil manche Befehle in Sprachen unterschiedlich funktionieren.
Programmieren kann man in vielen Sprachen
Das führt mich zum zweiten Punkt: Es ist ein bisschen egal, welche Sprache man lernt. Das trifft grundsätzlich zu, wenn man gängige Sprachen lernt und dann wechselt – das trifft aber besonders für die zwei gängigen Sprachen im Datenjournalismus zu: Python und R.
Python stammt eher aus der Informatikszene, R aus der Statistik. Python ist daher eher das Allroundtalent, R setzt einen starken Fokus auf statistische Auswertungen und die Kommunikation von Ergebnissen (in Grafiken, HTML, PDFs, Markdown-Dokumenten).
Was aber nicht heißt, dass die riesigen Communities um die beiden Sprachen nicht schon fast jede denkenswerte Erweiterung geschrieben haben, mit denen in Python und R quasi alles möglich ist. So sind Python und R eigentlich Workflow-Programme. Man kann von Anfang bis Ende ein Problem darin bearbeiten.
Programmieren für Journalisten: Lerne eine Sprache gut
Deswegen bleibt am Ende vermutlich nur dieser Tipp: Lerne eins von beidem gut – im Zweifel kannst Du dann auch das andere bedienen, falls Du eine ganz spezielle Funktion willst.
Ich habe mich zum Beispiel recht früh für R entschieden [In einem anderen Post habe ich schonmal beschrieben, wie ich R gelernt habe] – aber Python bekomme ich notfalls auch noch hin, wenn ich es brauche. Inzwischen geht sogar ein bisschen Javascript (was dann aber einfach nochmal neue Möglichkeiten eröffnet – eher in Richtung Datenvisualisierung als für Datenanalyse).
Und wo lernt man? Da gibts quasi für jeden Geschmack das passende (ich finde aber: auf Deutsch gibts zu wenig): Tutorials, Bücher, Workshops auf Konferenzen.
Kostenlose Onlineressourcen:
R for Journalists: Ist aus einem MOOC entstanden, gibts jetzt als digitales Buch
Coding for Journalists in Python: Ähnlich wie R, nur eben in Python
Kostenlose Bücher (gibts auch gedruckt zu kaufen):
R for Data Science (Hadley Wickham)
R Programming for Data Science (Roger D. Peng)
Und natürlich gibts auch kostenpflichtige Kurse (mit mehr Anleitung und kleineren Schritten):
Der Klassiker: Datacamp (150-300 US-Dollar im Jahr)
Coursera
EdX
Auch gut:
Journocode,
das Lede-Programm in New York,
Seminare, wie das ifp-Coding-Cootcamp [Disclaimer: Da hab ich auch schon unterrichtet]
oder Studiengänge an den Unis Leipzig, Dortmund oder in Cardiff
Fazit: Programmieren kann für viele Journalisten Sinn machen – für Datenjournalisten ist es inzwischen Standard.
Auch Anna hat ein paar Punkte aus unserem Gespräch zusammengefasst: