Im Internet stehen so viele Informationen. Ein Paradies für Datenjournalisten, die große Mengen an Informationen automatisiert abfragen wollen. Manchmal ist es einfach, an sie heranzukommen, manchmal etwas schwieriger. Denn manche Webseiten laden ihre Daten nicht in den Quellcode – dort, wo die einfachen Lösungen zum sogenannten Webscraping (über Scraping mit Python habe ich schon mal gebloggt) ansetzen. Doch mit ein bisschen Aufwand, können Datenjournalisten auch Seiten abfragen, die ihre Inhalte nachladen oder über Skripte generieren. Der einfachste Anwendungsfall ist aber: Der Weiter-Button.
Neulich hatte ich einen Fall, in dem ich knapp 1500 Daten von Abgeordneten abrufen wollte. Sie waren über eine Suche zugänglich, wurden allerdings nur in Hunderterschritten angezeigt. Ich habe ein Skript geschrieben, dass die Suche startet, jede Seite aufruft, die Informationen speichert und nach allen Abgeordneten auf einer Seite den Weiter-Button drückt. Später kann ich dann jede einzelne Abgeordnetenseite herunterladen.
Zum Glück gibt es „Selenium“. Das ist ein Framework, das ursprünglich dafür entwickelte wurde, um Tests in Browsern zu automatisieren. Um also schnell testen zu können, ob Softwareupdates irgendein Problem für die Nutzer erzeugen. Selenium ahmt dafür das Verhalten eines Nutzers im Webbrowser nach. Es kann Felder ausfüllen, Buttons anwählen oder einen Mausklick simulieren.
Eigentlich basiert Selenium auf HTML und Javascript, für R gibt es aber (wie so oft, zum Glück) ein Package, das die Funktionen anbietet: RSelenium. Für die Extraktion der Informationen benutze ich rvest, eine weitere R-Bibliothek, die HTML-Code in R durchsuchbar macht.
RSelenium im Einsatz
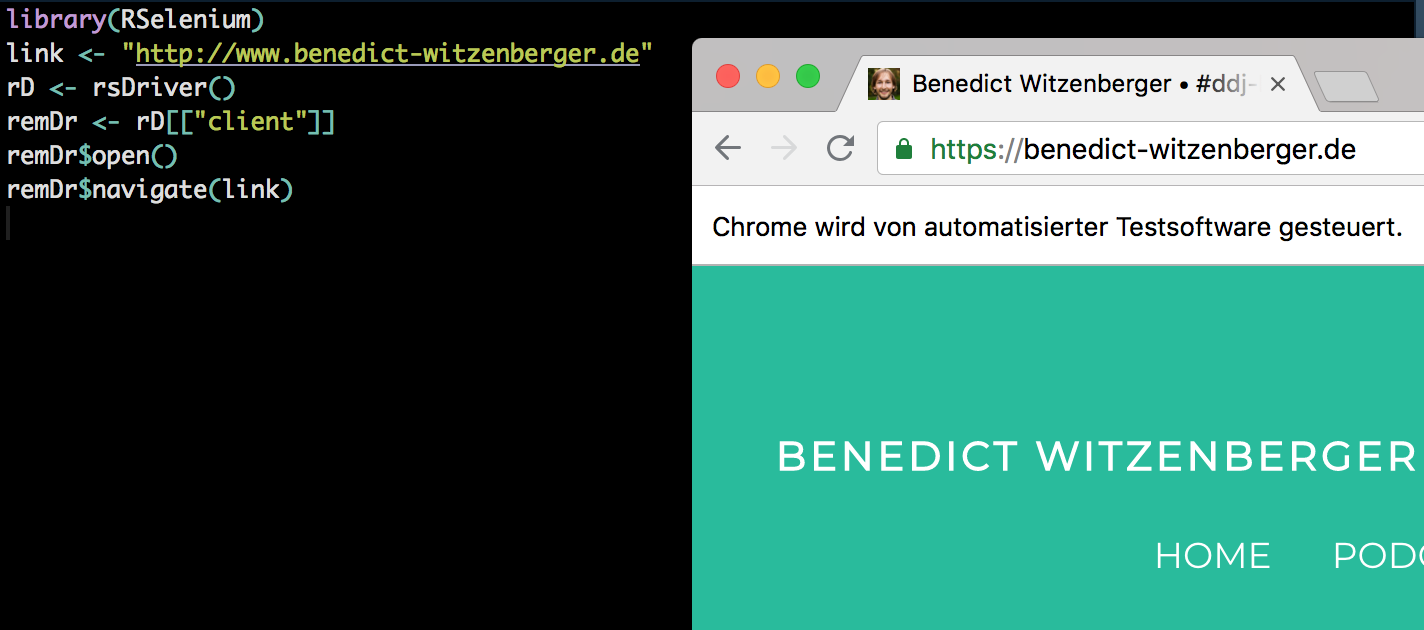
RSelenium hat zwar eine gute Dokumentation, ich musste trotzdem viel rumprobieren, weswegen ich hier mal meine Vorgehensweise dokumentiere. Um rechtlich nicht angreifbar zu sein, habe ich den Namen der URL gelöscht.
Zunächst laden wir die beteiligten Bibliotheken. rvest und RSelenium erwähnte ich bereits, tidyverse ist eine Sammlung von mehreren R-Packages, die für die Arbeit mit Dataframes (also einer Tabelle) in R benutzt werden.
|
1 2 3 |
library(rvest) library(tidyverse) library(RSelenium) |
|
1 2 3 4 |
# Start RSelenium link <- "" # hier steht der Link, den ich gelöscht habe - dort startet RSelenium rD <- rsDriver() remDr <- rD[["client"]] |
RSelenium startet auf einem lokalen Server und lädt dann ein neues Fenster in R. Darin wird ein Browser geöffnet, über den ich nachvollziehen kann was meine Befehle in R bewirken. remDr ist quasi der Browser, den ich steuere. Zum Beispiel lasse ich ihn einen Link öffnen – auf die erste Seite mit den Ergebnissen:
|
1 |
remDr$navigate(link) |
Insgesamt habe ich 14 Ergebnisseiten. Die habe ich händisch abgezählt für den Loop. Alternativ hätte ich auch eine Funktion schreiben können, die erkennt, wenn es keinen Weiter-Button mehr gibt.
14 Mal wiederholt R also den folgenden Vorgang: Es ruft eine Ergebnisseite auf, speichert dann den Link zur Detailseite jedes Abgeordneten, und klickt am Ende der Seite auf den Weiter-Button, den ich hier über seinen sogenannten X-Path finde. Dafür suche ich das Element auf der Seite, das den Text „nächste Treffer“ enthält. Und das ist nur der Weiter-Button.
|
1 2 3 4 5 6 7 |
for (i in seq_along(1:14)) { print(i) try(next_button <- remDr$findElement(using = 'xpath', "//*[contains(text(), 'nächste Treffer')]")) try(next_button$clickElement()) Sys.sleep(5) remDr$setImplicitWaitTimeout(5000) html_current <- read_html(remDr$getPageSource()[[1]]) |
Wir sind immer noch im Loop. Ich schreibe auf jeder Seite die Datenin Vektoren. Die Standardherangehensweise beim Webscraping ist allerdings: Detailseite öffnen und dann downloaden. Die Details kann ich dann auf meinem lokalen Rechner extrahieren, ohne unnötigen zusätzlichen Webtraffic bei der Seite zu erzeugen. Das werde ich auch hier tun. Ich sammle ja gerade die Links zu jeder Detailseite. Allerdings auch Namen und eine Information zu den Legislaturperioden der einzelnen Abgeordneten.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
html_current %>% html_nodes(".t_text:nth-child(1) a") %>% html_attr("href") -> urls_current urls <- c(urls, urls_current) html_current %>% html_nodes(".t_text:nth-child(1)") %>% html_text() %>% trimws() -> last_name_curr last_name <- c(last_name, last_name_curr) html_current %>% html_nodes(".t_text:nth-child(2)") %>% html_text() %>% trimws() -> first_name_curr first_name <- c(first_name, first_name_curr) html_current %>% html_nodes(".t_text:nth-child(4)") %>% html_text() %>% trimws() -> length_lt_curr length_lt <- c(length_lt, length_lt_curr) Sys.sleep(5) } |
5 Sekunden lasse ich das Skript hier am Ende ruhen, damit ich nicht zu viel Last auf dem Server erzeuge. Das ist allerdings schon eine sehr lange Zeitspanne.
Während das Skript läuft, kann ich weiterarbeiten. Die R-Bibliothek BeepR spielt einen Sound ab, wenn alle Dateien heruntergeladen wurden. Dann verbinde ich die einzelnen Vektoren zu einem Dataframe in R, mit dem ich dann fortfahren kann. In meinem Fall loope ich jetzt über die einzelnen Links und lade die Dateien herunter. Das hätte ich aber natürlich auch schon im Schritt oben machen können. Ich habe mich aber dagegen entschieden, weil ich erstmal alle Links bekommen wollte, und mit denen dann weiterarbeiten kann.
|
1 2 3 |
beepr::beep() df_abgeordnete <- cbind(first_name,last_name,urls,length_lt) |
Am Ende stoppe ich den Seleniumbrowser, der lokal auf meinem Rechner lief.
|
1 2 3 |
remDr$close() # stop the selenium server rD[["server"]]$stop() |
Fertig.
