Das Coronavirus hat im digitalen Journalismus viel angeschoben. Zum Beispiel beim Thema automatisierte Grafiken. Ein paar Tipps, wie ich mit Skripten und Datawrapper Grafiken update.
Dieser Blogpost ist schamlose Werbung für mein R-Package DatawRappr. Das hatte ich zufällig Ende 2019 entwickelt, hauptsächlich um die API von Datawrapper aus R heraus nutzen zu können.
Inzwischen nutzen es viele DatenjournalistInnen, um ihre Grafiken für das Coronavirus zu updaten. Seit Beginn der Pandemie habe ich einige Lösungen damit entwickelt, um „fancy“ Sachen zu machen – ein paar davon wollte ich hier teilen. Ein bisschen nerdiger Post diesmal.
1. Viele Grafiken auf einmal erstellen
Ein klassischer Anwendungsfall: Wir haben eine Grafik und hätten die gerne für verschiedene Ausprägungen ausgegeben. Zum Beispiel: Ein Liniendiagramm der Neuinfektionen für alle Länder in der EU. Wie kann ich diese Grafiken – die alle gleich aussehen – am einfachsten hintereinander weg erstellen?
Das geht ganz einfach über einen For-Loop (R-Enthusiasten werden an dieser Stelle darauf hinweisen, dass man dafür doch auf jeden Fall die apply-Familie oder das Package purrr verwenden sollte. Macht auch Sinn, aber vermutlich ist es für Leute aus anderen Programmiersprachen einfacher, wenn wir erstmal bei for bleiben.)
Wie gehen wir vor?
- Wir erstellen für ein Land die Grafik in Datawrapper so, wie sie aussehen soll.
- Lade die Metadaten dieser Grafik in R:
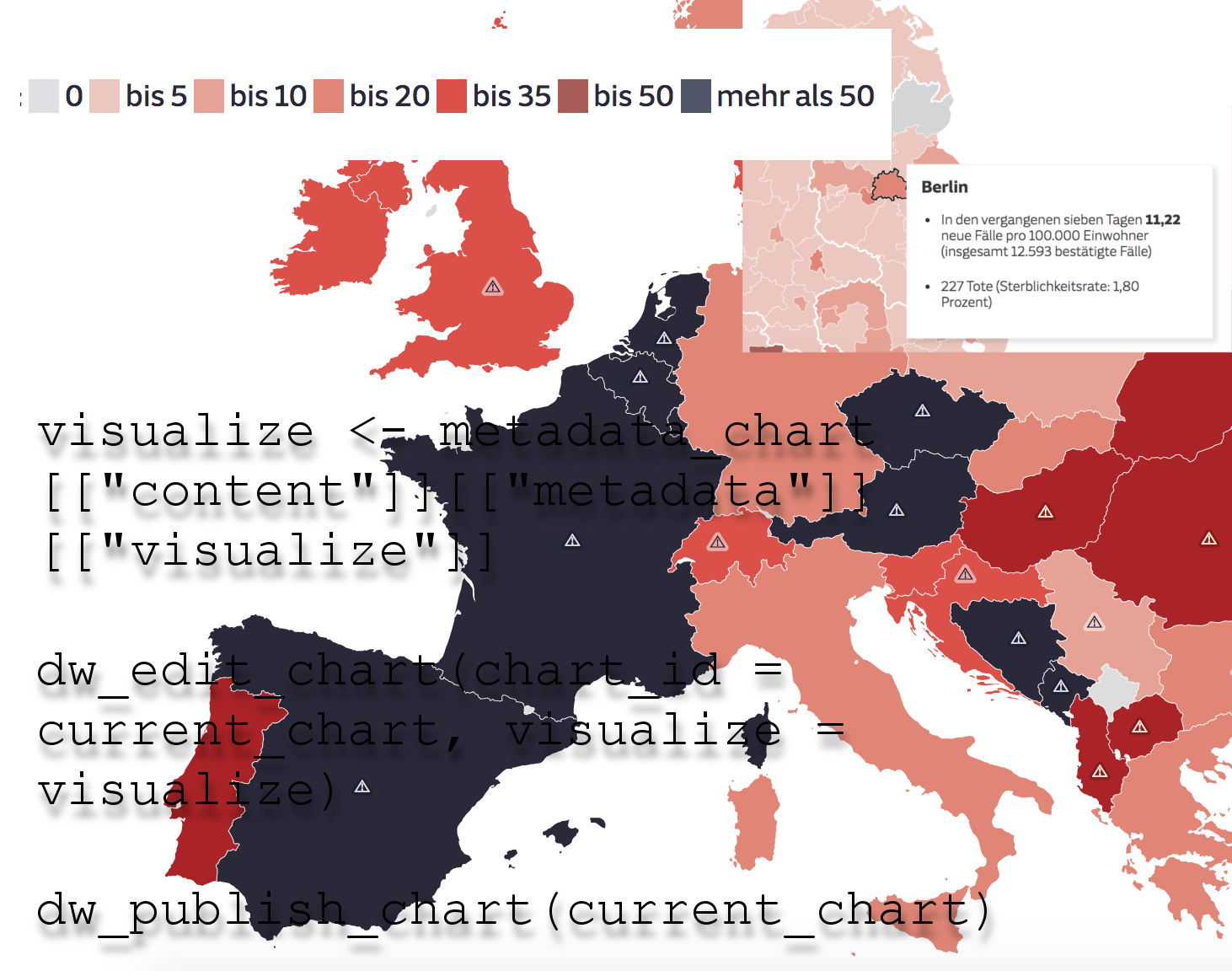
metadata_chart <- dw_retrieve_chart_metadata(chart_id, api_key) - Wir speichern den
visualize-Abschnitt der Metadaten lokal ab. Zum Beispiel alsvisualize.RData:visualize <- metadata_chart[["content"]][["metadata"]][["visualize"]]saveRDS(visualize, "visualize.RData") Visualizeenthält alle optischen Vorgaben unserer Grafik. Wir können die der API mitgeben, wenn wir eine neue Grafik erstellen.
Jetzt geht also der Loop los – über einen Vektor mit den Ländern. Grundsätzlich sieht der irgendwie so aus:for (Land in Laender_liste) {
rohdaten %>%
filter(Staat_in_Rohdaten == Land)
}- Für jedes dieser Länder erstellen wir eine neue Datawrapper-Grafik mit
dw_create_chart(). Die neue Chart-ID bekommen wir direkt von der API zurückgeliefert und können sie im weiteren Verlauf benutzen:current_chart <- dw_create_chart(title = paste0("Chart für ", Land),type = "d3-lines") - Damit auch die Visualisierungen richtig angezeigt werden, schicken wir der neuen Grafik direkt noch ein
dw_edit_chart()hinterher:dw_edit_chart(chart_id = current_chart, visualize = visualize)
[Eventuell kann man an dieser Stelle auch schon Daten mitdw_data_to_chart()hochladen.] - Praktisch wäre es jetzt noch, wenn wir einen Überblick bekämen über alle Iframes und URLs unserer neu erstellten Grafiken. Dafür nutzen wir die
dw_publish-chart-Funktion. Die kann ein Objekt zurückgeben, das die gewünschten Infos enthält und die wir abspeichern.
Vor unseren Loop erstellen wir dafür eine leere Liste…result_list <- list()… die wir in jedem Loop-Durchgang (also für jedes Land) weiter befüllen:published_chart <- dw_publish_chart(current_chart)
result_list[[i]] <- data.frame(id = area_id, country = area_name, url = published_chart$publicUrl, iframe = published_chart$iframeCode, chart_id = published_chart[["content"]][["data"]][[1]][["id"]]) - Die Grafiken sind erstellt. Damit wir beim Aktualisieren auch alle Chart-IDs beisammen haben, speichern wir
result_listam besten irgendwo lokal als Dataframe ab:result_df <- dplyr::bind_rows(result_list)
saveRDS(result_df, "chart_ids.RData") - Für die Aktualisierung loopen wir dann einfach über
result_listund verändern die Charts: die Daten mitdw_data_to_chart, die Titel, Introtexte oder Anmerkungen mitdw_edit_chart.
Den gesamten Code für so einen Loop habe ich hier in einem Github Gist verlinkt.
2. Datawrapper-Grafiken als Bilder ausgeben
In einem weiteren Schritt können wir aus den vielen Grafiken auch Bilder erstellen. Zum Beispiel für einen Small-Multiple-Überblick sein. Also viele kleine Grafiken nebeneinander.
Wir können dafür wieder den vorherigen Loop verwenden. Dazu die Funktion dw_export_chart():png_chart <- dw_export_chart(
chart_id = current_chart,
type = "png",
unit = "px",
mode = "rgb",
width = 200,
height = 300,
plain = TRUE,
scale = 2)
In diesem Beispiel geben wir ein PNG mit 200 Pixeln Breite und 300 Pixeln Höhe aus, doppelt skaliert (scale), Titel und Anmerkungen werden nicht angezeigt (wegen: plain = TRUE). Mit der Funktion image_write aus dem magick-Package können wir die Grafiken dann lokal speichern:
image_write(png_chart, "output.png")
Dann laden wir die Bilder irgendwo hoch, und bauen mit HTML eine Überblicksseite, in die wir alle einbinden.
3. Tooltips über die Datawrapper-API verändern
Karten und Scatterplots in Datawrapper können beim Hovern oder Klicken Tooltips anzeigen. Auch die kann man ziemlich einfach über die API verändern. Das kann zum Beispiel praktisch sein, wenn man bestimmte Daten dynamisch dazugibt oder eben nicht.
Ein Beispiel: Ich scrape für eine Zusatzinfo eine bestimmte Seite. Diese Info will ich eigentlich immer in meiner Grafik anzeigen, aber was, wenn die Seite plötzlich offline ist? Ich könnte auf ein Fallback zurückspringen, ich kann mich aber auch entscheiden, diese Info dann nicht anzuzeigen. Dafür muss ich die Tooltips verändern können.
Am einfachsten ist das Vorgehen, wenn ich die Tooltips über das grafische Nutzerinterface anlege. Ich kann sie dann über dw_retrieve_chart_metadata() ganz einfach abrufen und verändern. Der Tooltip liegt unter: metadata_chart[["content"]][["metadata"]][["visualize"]] und besteht aus drei Abschnitten:
body: ist der Haupttext des Tooltipps. Der Inhalt kann mit HTML und CSS strukturiert werden (wie auch im GUI). Um Variablen aus den Daten zu verwenden nutzt man dieses Format:{{ variable_name }}.title: ist – wie der Name vermuten lässt – die Überschrift des Tooltips. Auch hier kann man Variablen verwenden, wie im body.fields: ist eine Liste, die die Zuordnung von Variablen im Tooltip und Variablen in den Daten festlegt. Zum Beispiel so:fields = list("variableTooltip1" = "VariableData1","variableTooltip2" = "VariableData2")
Im einfachsten Fall heißen die beiden Variablen einfach auf beiden Seiten gleich.
Um den Tooltip zu verändern nutzen wir dw_edit_chart():
dw_edit_chart(chart_id, visualize = list(
tooltip = list(
body = "{{ variableTooltip1 }} has value {{ variableTooltip2 }}.",
title = "{{ variableTooltip1 }}",fields = list(
"variableTooltip1" = "VariableData1",
"variableTooltip2" = "VariableData2"
)
)))
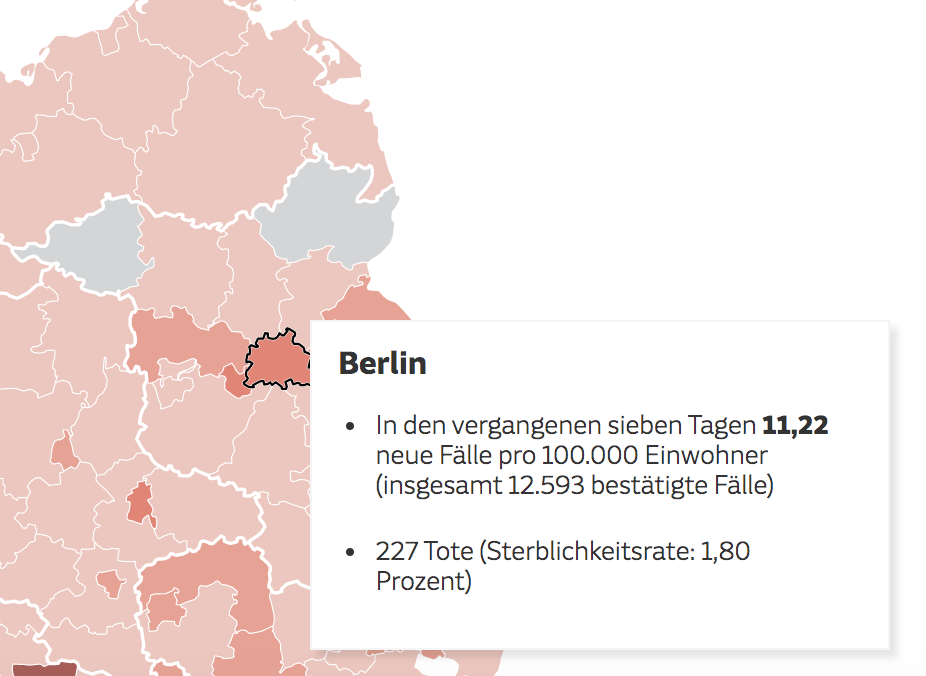
4. Kartenlegende handy-freundlich
Datawrapper hat inzwischen richtig viele Möglichkeiten, Karten zu erstellen. Gerade bei Choroplethenkarten gibt es aber ein Problem: Auf kleinen Bildschirmen wird die Karte so weit zusammengestaucht, dass die Legend oft Teile der Daten überlagert – und manche Bereich dadurch nur schwer zu lesen sind. Ein Workaround ist es, den Zoom einzuschalten. [Edit: Am 29.09.20 hat Datawrapper ein großes Update veröffentlicht – mit neuer Legende]
Eine andere Variante: Die Legende in die Unterzeile der Grafik zu verlagern. So geht man dafür vor:
- Erstelle eine Choroplethenkarte in Datawrapper: Suche eine Basiskarte aus, und verbinde die Karte mit den Daten (über eine gemeinsame Spalte, z.B. die AGS, oder ISO-Codes). Überprüfe dann einmal kurz, ob die Legende auf der Karte richtig angezeigt wird. [Das geht auch mit DatawRappr]
- Lade die Metadaten der Karte in einem R-Skript:
metadata_chart <- dw_retrieve_chart_metadata(chart_id, api_key) - In
metadata_chartfinden wir dann alle Infos, die unsere Karte beschreiben. Die Legende finden wir im Abschnittmetadata_chart[["content"]][["metadata"]][["visualize"]][["categories"]]. Der Einfachheit halber können wir diesen Abschnitt auch einfach schnell als Variable rausziehen:new_legend <- metadata_chart[["content"]][["metadata"]][["visualize"]][["categories"]] - Diesen Abschnitt geben wir in die neue Funktion
dw_legend_to_string. Sie gibt die Legende dann als HTML-Code zurück (alternativ auch als Textstring oder Vektor), die wir einfach als Unterzeile in Datawrapper hinterlegen können:intro_text <- dw_legend_to_string(new_legend, return_val = "html") - Wir updaten die Grafik mit:
dw_edit_chart(chart_id, api_key, intro = intro_text)
So sieht das Ergebnis aus:



