
Es gibt momentan nur ein Thema: das Coronavirus. Covid-19 bringt Nachrichtenwebseiten Rekordzugriffszahlen und Datenjournalisten große Aufmerksamkeit. Allerdings birgt das Thema auch manche Probleme. Ein paar Gedanken.
Mysteriöse Lungenkrankheit in Zentralchina ausgebrochen
dpa, 31. Dezember 2019
So lautet die Überschrift einer kleinen Meldung der dpa am Ende des vergangenen Jahres. 27 Erkrankte hatten die Gesundheitsbehörden in Wuhan damals vermeldet. Heute, knapp vier Monate später, liegt die Zahl der bestätigten Coronavirus-Infizierten weltweit deutlich über der Millionenmarke.
In Deutschland leben wir seit einigen Wochen unter Ausnahmebeschränkungen, wir arbeiten teilweise von zuhause, gehen kaum noch raus, treffen keine anderen Menschen. Es wundert daher vermutlich kaum, dass die Menschen in dieser Zeit ein sehr hohes Informationsbedürfnis haben. Sehr erfreulich für die „klassischen Medien“ ist die Beobachtung, dass die Nutzer dieses Bedürfnis anscheinend verstärkt auf den Nachrichtenwebseiten und im öffentlich-rechtlichen Rundfunk gestillt haben möchten. Nicht auf Seiten mit „alternativen Fakten“ oder Verschwörungstheorien im Internet. Auch wenn diese durchaus auch aufblühen.
Gerade für Datenjournalisten gibt es in dieser Krise viel zu tun:
- Es gibt sehr viele Daten, die verständlich visualisiert werden sollten.
- Es gibt viel Unsicherheit in den verwendeten Modellen, die richtig interpretiert und kommuniziert werden muss.
- Es herrscht ein enormer Druck, neue Entwicklungen zeitnah abzubilden, ohne „falsche“ Zahlen zu verbreiten.
- Andererseits gibt es keine „richtigen“ Zahlen. Denn wir werden nie die korrekte Zahl aller Infizierten abbilden können. Auch das müssen wir immer wieder klarmachen.
Zu Beginn der Krise ging es uns hauptsächlich um klassische Visualisierungen. Vor allem ging es um die Frage: Wie groß ist die Zahl der Infizierten anderswo? Solange das Virus nur in China nachgewiesen war, gab es eine zentrale Quelle. Doch dann begann es auch in anderen Staaten aufzutauchen. Wir brauchten eine neue Quelle, die im Idealfall die ganze Welt abdeckt.
Wo kommen die Daten her?
Vor allem zu Beginn des Coronvirus-Ausbruchs in China (und für alle Länder außer Deutschland auch weiterhin) haben wir die Daten der Johns-Hopkins-Universität verwendet. Die Forscher dort sammeln die Daten zu Infizierten und Verstorbenen pro Land in einem Dashboard, das mehrmals am Tag aktualisiert wird. Und machen die zugrundeliegenden Daten einmal täglich auch über ein Github-Repository zugänglich. Bis Mitte März wurden außerdem die Zahlen der genesenen Patienten veröffentlicht. Das wurde inzwischen eingestellt. Vermutlich ist die Arbeitslast deutlich gestiegen, seitdem Covid-19 auch in den USA angekommen ist – denn für dort ermittelt die Johns-Hopkins sogar die Zahl der Tests.
Johns-Hopkins ermittelt die Zahl nicht nur aus offiziellen Bekanntmachungen, sondern arbeitet unter anderem auch mit Medien zusammen, die kleinräumigere Daten sammeln und vor allem schneller sein sollen, als die amtlichen Statistiken. Denn je schneller wir wissen, wie sich die Zahlen verändern, umso schneller können Politik und Medizin darauf reagieren.
Die deutschen Zahlen für das JHU/CSSE-Dashboard kommen über Umwege von den Kolleginnen und Kollegen des Funke Interaktiv-Teams – die sie wiederum von den Landesgesundheitsämtern sammeln:
Außerdem nutzt die JHU Zeit Online und den Berliner Tagesspiegel als Quelle. Vermutlich über den Umweg Worldometers, einer Datenwebseite des Unternehmens Dadax. [Tagesschau.de hat versucht, das nachzuzeichnen.]
Fazit: Die Johns-Hopkins ist eine gute Quelle für die weltweiten Zahlen. Vermutlich nicht stundenaktuell, aber für einen Eindruck ausreichend. Aber gerade für Deutschland und die einzelnen Bundesländer wollen wir eigentlich aktuellere und direktere Daten. Die erste Anlaufstation wäre die zuständige Stelle auf Bundesebene:
Probleme mit dem Robert-Koch-Institut
Das Robert-Koch-Institut wurde in der Berichterstattung immer wieder kritisiert. Teilweise dauerte es mehrere Tage, bis die Zahlen dort den Stand der Johns-Hopkins-Zahlen erreichten. Der Grund: Der lange amtliche Übertragungsweg über die Gesundheitsbehörden der Kreise, zu den Gesundheitsministerien der Länder, zum RKI. [Mehr zu diesem Prozess hat mein Kollege Christian Endt hier aufgeschrieben.] Inzwischen sind die Zahlen des RKI auf ein neues, elektronisches Meldesystem umgestellt worden. Aber eine Verzögerung lässtsich auch dadurch nicht vermeiden. Wir versuchen deshalb, wo es geht, auf die RKI-Zahlen zu verzichten.
Wie machen das andere Länder (zugegebenermaßen immer mit anderen Vorraussetzungen)?
- Sciensano, das belgische Gesundheitsinstitut, publiziert inzwischen die Zahl der Infizierten, die Zahl der Tests, die Zahl der Covid-19-Patienten im Krankenhaus und die Zahl der Verstorbenen täglich auf Provinzebene. Und das ganze als Excel, CSV und JSON – also herausragend machinenlesbar.
- Italien veröffentlicht seine Infiziertenzahlen in einem Dashboard und als Open Data (sogar in Englisch) auf Github.
- Sogar der „berüchtige“ britische NHS lässt einen Teil seiner regulären Datensammlungsaufgaben ruhen, um mehr Kapazitäten für die Daten zu Covid-19 zu haben.
Auch das Robert-Koch-Institut ermöglicht über ein Dashboard seit etwa einer Woche auch den Zugang zu sehr viel kleinräumigeren Daten, als zu Beginn der Krise. Und dank dem Geodaten-Anbeiter ESRI werden die Daten hinter dem Dashboard als Open Data angeboten.
Das bedeutet übrigens nicht, das das RKI gerade einen besonders schlechten Job macht. Immerhin werden überhaupt Daten veröffentlicht. Und zwar sehr regelmäßig und mit zunehmender Detailtiefe. Aber: Der langsame Start und die Probleme bei der Übermittlung (teilweise kommen am Wochenende aus manchen Orten keine Meldungen) zeigen einfach, wie schlecht es um Open Data in vielen Bereichen der öffentlichen Verwaltung in Deutschland bestellt ist. Wen das genauer interessiert, der sei auf die Experten dazu verwiesen: zum Beispiel die OpenKnowledgeFoundation.
Es gibt auch private Datensammler
Dass die Datenbasis in Deutschland besser wird, haben wir Initiativen wie Risklayer zu verdanken. Das ist eine Kooperation des Center for Disaster Management and Risk Reduction Technology (CEDIM) am Karlsruher Intitut für Technologie undRisklayer, einer Analysedatenbank zur Risikobewertung. In Kombination mit einem Crowdsourcing und smartem Webscraping werden so viele Quellen (Landesgesundheitsämter und lokale Behörden) kombiniert. Das Ergebnis: Ziemlich aktuelle und kleinräumige Daten. (Eine weitere, wenn auch inoffizielle Quelle ist coronavirus.jetzt). Bei dem Tagesspiegel habe ich Risklayer auch schon als Quelle in Grafiken entdeckt.
Wie wir unsere Coronavirus-Daten sammeln
Auch wir standen vor dem Problem, wie wir unseren Leserinnen und Lesern aktuelle Zahlen, am besten für alle Bundesländer anbieten können. Dabei haben ein paar Kollegen aus der Politikredaktion ein einfaches Verfahren entwickelt: Ein Googlesheet. Sie recherchieren für jedes Bundesland die aktuellsten Zahlen und tragen sie in das Sheet ein. Der Vorteil: Wir müssen uns nicht auf eine Quelle verlassen, die möglicherweise langsam ist. Der Nachteil: dieser Job bleibt bei Menschen hängen.
Damit wir diese Menschen dafür an anderer Stelle entlasten, haben wir sehr viele Grafiken automatisiert. [Wer sich für die Skripte dahinter interessiert, findet einen Stand auf dem SZ-Github-Account. Die Automatisierung funktioniert über das DatawRappr-Package]. Jede halbe Stunde werden inzwischen an die zehn Grafiken automatisch auf den neuesten Stand gebracht. Ohne, dass jemand händisch etwas dafür tun muss.
Für die deutschen Bundesländer verwenden wir also Daten aus der eigenen SZ-Recherche, für die ganze Welt nehmen wir Johns-Hopkins. Aktuell haben wir noch eine Karte mit den deutschen Kreisen – dafür nehmen wir Daten des RKI, normalisiert auf 100.000 Einwohner.
Normalisierte Karten zum Coronavirus?
Über die Frage „Normalisieren oder nicht?“ gab es einige Diskussionen unter deutschen Datenjournalistïnnen auf Twitter. Als es nur wenige Fälle weltweit (oder auch in Deutschland gab) plädierten viele (auch wir) dafür, die Zahl der Fälle absolut zu zeigen, als Kreise. Warum?
Je kleiner die Zahl der Fälle, umso eher steckt dahinter eine einmalige Ansteckungsgeschichte. Die Kappensitzung im Kreis Heinsberg, mutmaßlich das Starkbierfest in Mitterteich. Diese Fälle stechen heraus. Solange ein Virus nicht halbwegs regional breit gestreut ist (wie Verbrechen oder Autounfälle) macht eine Normalisierung wenig Sinn. Ja, in China leben viele Menschen. Ja, die Ansteckung durch ein Virus hängt bestimmt auch damit zusammen, wie dicht Menschen zusammentreffen. Aber eben nicht nur. Außerdem (so mein Eindruck) interessiert viele Menschen die absolute Zahl der Erkrankten in ihrer Nähe. Wir haben deswegen lange auf eine Normalisierung verzichtet. Inzwischen nutzen wir sie auf der oben angesprochenen Karte der deutschen Landkreise.
Aber: Solche Entscheidungen bleiben nicht ohne Debatte. Innerhalb und außerhalb des Teams.
Von Grafiken zum Coronavirus-Dashboard
„FlattenTheCurve“ geisterte vor wenigen Wochen durch soziale Netzwerke. Eine wesentliche Variable davon ist aber auch: Die Verdopplungsrate. Wie schnell verdoppelt sich die Zahl der Infizierten? Bundeskanzlerin Merkel gab die Marke von zehn Tagen aus, ab der man über die Aufhebung der Ausgangsbeschränkungen sprechen könnte. Diese Verdopplungszahl haben wir seit einigen Wochen als festes Element in einem Dashboard auf der Homepage untergebracht. Sie soll ein bisschen weiterführen. Und ist eine eigene Berechnung aus den vorhandenen Daten.

Vor allem bei der Spalte „Trend“ haben wir gemerkt, wie hoch das öffentliche Interesse aktuell ist. Noch nie habe ich so viele Lesermails bekommen. Sehr interessant war, wie sich die Menschen darin geäußert haben. Während die Debatte auf Twitter in vielen Fällen sachlich und konstruktiv war (auch das ist bemerkenswert), hatten wir in vielen Mails das Gefühl, man wollte uns grundsätzlich unterstellen, dass wir keine Ahnung hätten und unsere Darstellung völlig falsch sei. Als ob wir uns nichts dabei gedacht haben. Die konstruktiven Mailschreiber haben aber dankenswerterweise viel wertvolles Feedback geschickt.
Wie die Datenjournalistenszene mit Covid-19 umgeht
Sehr schön finde ich den Ansatz, dass inzwischen fast jedes DDJ-Team ein Dashboard produziert hat. Alle haben einen bisschen anderen Angang – ich halte die Grundidee aber für total richtig, solange man mit einem Dashboard weiterhin eine Art „Story“ erzählen kann.

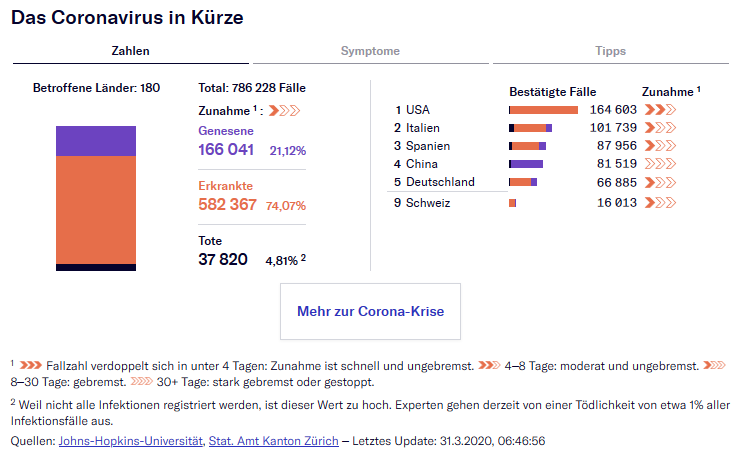



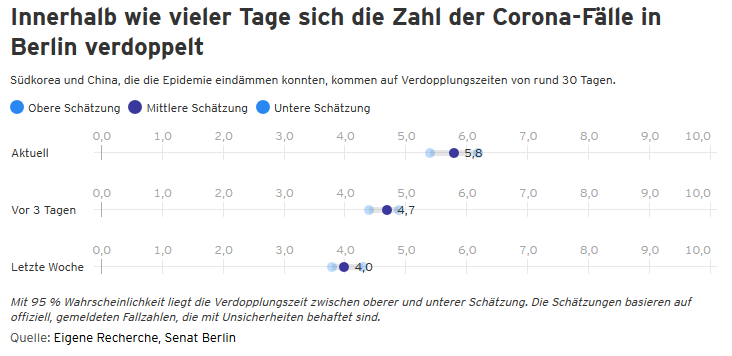
Es ist sehr spannend zu sehen, welch tolle Projekte das traurige Thema Coronavirus möglichmacht. Ich werde hier bestimmt ein relevantes vergessen, deswegen nur ein paar Beispiele:
- Harry Stevens von der Washington Post hat verschiedene Corona-Szenarien simuliert ($).
- Die New York Times zeichnet die Ausbreitung des Virus nach.
- Die Zeit sammelt die Daten aus allen 401 Gesundheitsämtern.
- Der Spiegel hat sich die Auswirkungen auf deutsche Innenstädte angeschaut.
- Mein Kollege Christian Endt hat exponentielles Wachstum erklärt.
- Mehrere Autorinnen und Autoren der SZ haben verschiedene Corona-Modelle für Deutschland durchgespielt (€).
Was können wir bis hierhin lernen?
- Austausch mit anderen Datenjournalisten hilft enorm, die eigene Arbeit zu verbessern. Und um zu sehen, dass alle ähnliche Probleme haben.
- In der Krise liegen Chancen – wir haben einen richtig hohen Output aktuell, können also auch viele neue Erzähl- oder Visualisierungsformen ausprobieren.
- Die Datenbasis ist nicht optimal. Aber sie verbessert sich. Das ist ein gutes Zeichen.
- Die FT, allen voran John Burn-Murdoch, sind die aktuellen Sterne am Datenjournalistenhimmel. Nicht nur, aber auch wegen dieser Grafik:

Die FT traut sich an ziemlich verrückte Darstellungen. Das hängt vermutlich auch mit ihrem eher zahlenaffinen Publikum zusammen. Um es einen Kollegen vom Spiegel formulieren zu lassen:
Das Coronavirus wird uns noch lange begleiten. Wenn man darin etwas Positives sehen will: Es hat die Datenjournalistenszene auf jeden Fall zu tollen Projekten angeregt.
Anmerkung:
Seit der Veröffentlichung habe ich einige Fakten im Text korrigiert:
Risklayer war nie eine Quelle von Zeit Online. Die sammeln ihre Daten in Kooperation mit Coronovirus.jetzt.
Die Daten der Johns-Hopkins-Universität für Deutschland haben neben Funke Interaktiv mindestens noch Zeit Online und den Tagesspiegel als Quelle. Tagesschau.de und NDR Data haben mehr dazu recherchiert. (Danke für den Hinweis, Julius)