
Schneller, tiefgehender und persönlicher sollen die Inhalte werden: Automatisierung im Journalismus ist ein ziemlich neues Feld. Und ein ziemlich spannendes.
Es ist eine Horrorvorstellung für viele Arbeitnehmer: Entlassen, weil der eigene Job jetzt von einem Computer gemacht werden kann. Besser und billiger. Zwischen 75 und 375 Millionen Jobs könnte das bis 2030 treffen, hat eine Studie von McKinsey mal geschätzt. Was man dabei aber nicht vergessen darf: Neue Jobs entstehen.
Im Journalismus sind das beispielsweise Berufsbilder im Automation-Bereich (im Deutschen oft unter dem Begriff „Roboterjournalismus“ – als ob da eine Maschine säße und in die Tastatur eintippt…). In den USA gibt es schon einige Newsrooms mit Automation-Editors, auch der BR startet gerade ein Automation und AI-Lab:
Und tatsächlich steckt sehr viel Potenzial im Bereich Automatisierung und Journalismus. Der US-amerikanische Journalistikforscher Nick Diakopoulos hat 2019 dazu das Buch „Automating the News“ veröffentlicht. Darin beschreibt er anhand vieler Beispiele im Groben vier Bereiche, in denen Automatisierung Journalisten und Medienhäusern helfen kann:
- Geschwindigkeit: Automatisierung kann Daten in wenigen Sekunden in vordefinierte Text-Templates füllen und veröffentlichen,
- Qualität: gerade Zahlen können ohne menschliches Zutun mit weniger Fehlern weiterverarbeitet werden – wenn die Input-Daten fehlerfrei sind,
- Breite: Automatisierung kann mehr Bereiche abdecken, als das menschliche Journalisten leisten können,
- und Personalisierung: mit Automatisierung können wir die Daten hervorheben, die die Nutzer persönlich betreffen.
(Ich habe mit Diakopolous ein Interview für die SZ geführt / Für das Nieman Lab hat er außerdem einen spannenden Post über das Thema geschrieben)
Die Überschneidung von Automatisierung und Journalismus hat ziemlich viele Facetten: Welche Datenquellen nehmen wir für die Automatisierung? Wie bringen wir den Computerprogrammen journalistische Grundsätze bei? Wie kontrollieren wir die Programme? Und wie machen wir kenntlich, dass nicht ein Mensch, sondern ein Skript einen Text verfasst hat?
Ich konzentriere mich in diesem Blogpost aber vor allem auf meine Erfahrungen aus der Praxis.
Automatisierung bei der SZ
Auch bei der SZ haben bisher vor allem Katharina Brunner und Martina Schories mit dem Thema Automatisierung experimentiert. Vom Datenjournalismus zur Automatisierung ist es auch kein sehr weiter Weg: Beide nutzen Daten, und bei beiden wird programmiert.
Im Projekt „Better Polls“ [hier auf Github] wurden Umfragen auf eine neue Art dargestellt – ohne absolute Werte, mit ihrem Fehlerbereich. So wie es inzwischen Medien auf der ganzen Welt machen: New York Times, FiveThirtyEight oder die BBC.
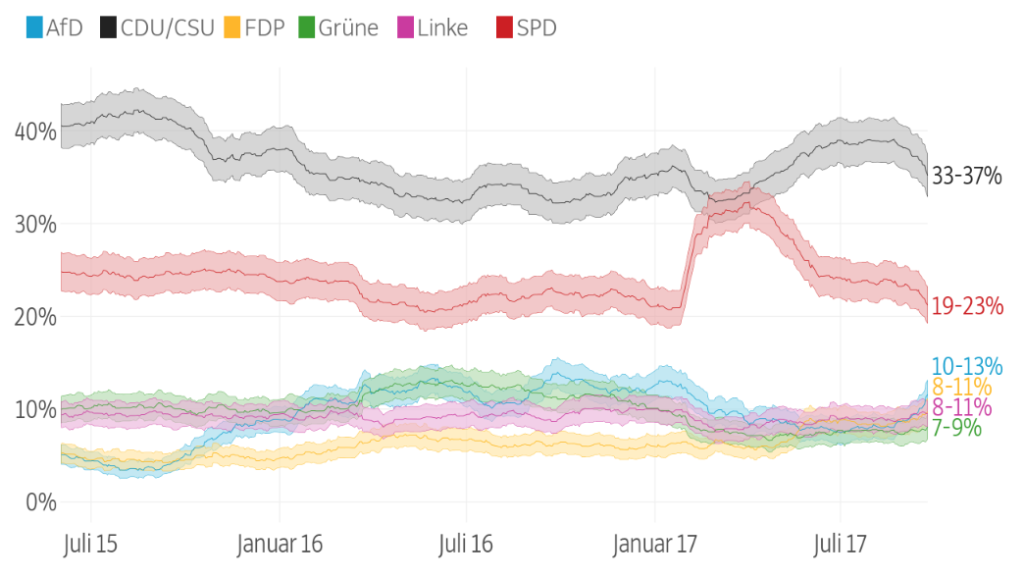
Bei den Bundestagswahlen 2017 und den Landtagswahlen in Bayern 2018 hat die SZ zum ersten Mal auf mit automatisch erstellten Texten gearbeitet. Wobei „automatisch“ nicht heißt, dass davor nicht ziemlich viel Arbeitsaufwand in Entwicklung, Berechnung und Testen gesteckt worden wäre. Für jeden Wahlkreis haben die Datenjournalistinnen damals das Wahlergebnis einzeln, als eigener Artikel über ein Skript ausgespielt und mit vielen Vergleichsgrafiken angereichert.
[Ein Beispiel gibt es hier]
Automatisierung für die US-Wahlen 2020
Und auch jetzt, im Beginn des US-Wahlkampfes 2020 haben wir uns wieder gefragt, wie wir unseren Nutzerinnen und Nutzern aktuelle Grafiken bieten können – ohne die ständig händisch aktualisieren zu müssen.
Für die US-Vorwahlen nutzen amerikanische Medien Umfrage-Aggregatoren. Sie berechnen also aus allen einzelnen Umfragen einen Mittelwert. Der Gedanke dabei: Umfragen sind immer mit Ungenauigkeiten behaftet. Bildet man aus Umfragen aber den Durchschnitt, so gleichen sich die verschiedenen Abweichung nach Oben und Unten im Idealfall wieder aus. Auch wir haben uns daher für eine solche Aggregation entschieden. Wir nutzen dabei die Daten von FiveThirtyEight, das alle Umfrageergebnisse verfügbar macht, und alle amerikanischen Umfrageinstitute nach ihrer Leistung einstuft. Wir können daher nur die besten Instituten auswählen.
Die Berechnung für unseren Mittelwert machen wir (wie so oft) in der Programmiersprache R. Am Ende entstehen zwei Grafiken. Ein Scatterplot mit Liniendiagramm für die nationalen Umfragen über die Zeit hinweg…
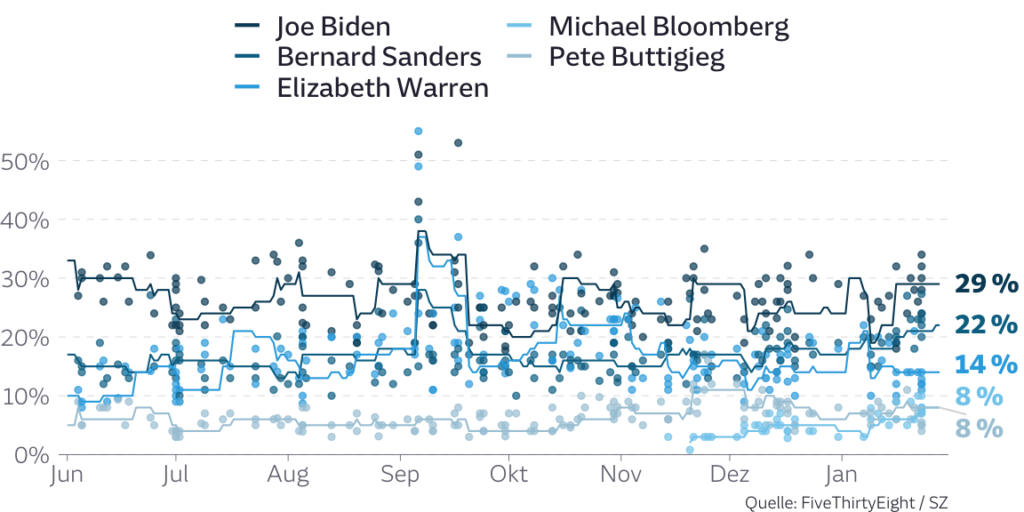
… und eine Tabelle in Datawrapper, die die Umfragen in den Einzelstaaten der kommenden Vorwahlen aggregiert:
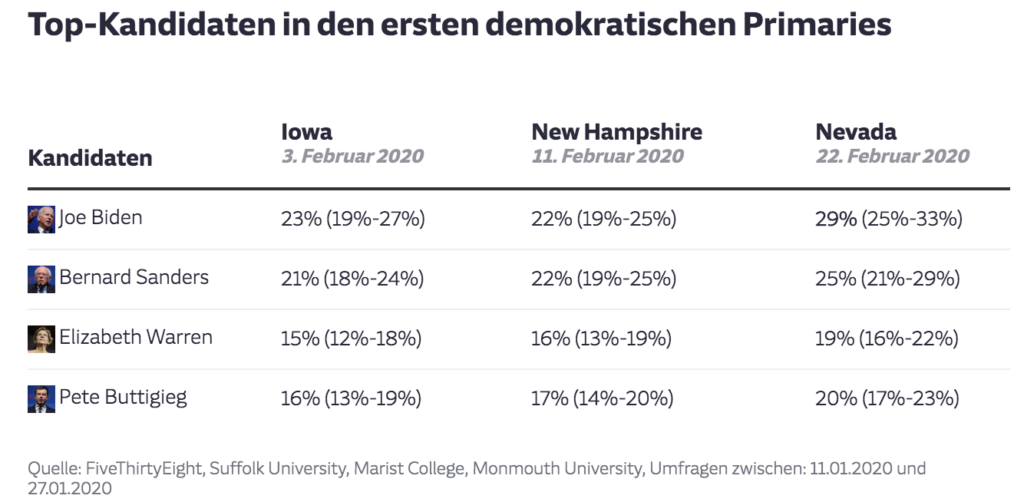
Die Tabelle befülle ich über das DatawRappr-Package, das ich neulich veröffentlicht habe.
Jeden Morgen um 5.30 Uhr läuft ein Skript auf unserem Server und aktualisiert die Umfragen. So haben wir einen immer aktuellen Überblick über das demokratische Rennen in den USA. [Hier der Link auf den Überblicksartikel zu den Vorwahlen auf SZ.de]
Weiterführende Links zu Automatisierung im Journalismus:
- Der Deutschlandfunk und Netzpolitik.org haben Überblickstexte zum Thema „Roboterjournalismus“
- Ziemlich spannend ist eine Studie der LMU München, die untersucht hat, wie automatisierte Text auf die Nutzer wirken.
Anmerkung: Ich habe bei den SZ-Beispielen nochmal präzisiert, wer die Projekte umgesetzt hat. War da ein bisschen zu pauschal.
